
by Matt Zimmerman

Scraping the Google search engine results page (“SERP”) is the solution for automatically seeding the AI’s brain with relevant and detailed knowledge about a topic.
Let’s talk high level for a moment.
The AI has a cutoff from a knowledge perspective. The cutoff for GPT 3.5 is 2021 and the cutoff for GPT 4 is 2023. But even if the AI has knowledge on a topic, it doesn’t mean the AI has deep knowledge on that topic.
So when you want to write an article about a topic the AI knows nothing about or a topic that could use some deep knowledge, then you should use the SERP scraping functionality inside ZimmWriter.
I think it’s important to share with you what goes on behind the scenes during a SERP scrape. Let’s discuss it from the perspective of the Bulk Writer in ZimmWriter:
Hopefully this high level overview not only sheds some light on what is going on behind the scenes, but also why it takes longer to write an article using SERP scraping than without.
The default setting for geolocation is United States (which uses google.com) and the default location is Houston, TX, United States. If all you want is to scrape google.com and don’t care about geolocation, then just leave everything alone and it will work beautifully.
IMPORTANT NOTE: The caching only works based on the input title and does not factor in the geolocation. So if you scrape a title in the United States and then ask to scrape it again in Canada, it will pull the cached United States scrape. To avoid this, you’ll need to check the overwrite cache box.
I covered most of how SERP scraping works in the bulk writer above, but there are a few more important points.
The SERP scraping menu has several options:
Here are a few more things to keep in mind in the Bulk Writer:
The SERP scraping button is found in step 2 of the SEO Writer menu.
Now one thing I need to explain first, and stress with utmost importance, is *when* the summaries from the up to 5 scraped websites are used in the SEO writer. The summaries not visible to you on the front end, but are used on the back end when writing the article.
In the Bulk Writer, the summaries are used to generate discussion points for each subheading.
But in the SEO Writer, the summaries are used to generate discussion points for any subheading that does not have a supplied “URL for scraping” and does not have “background info” supplied for that specific subheading.
Read that again a few times.
Now let me hammer it in by explaining it once more but in reverse. If you supply a URL in the “URL for scraping” box for a subheading or supply background information for a subheading, then the webpage summaries from the SERP scrape will not be used for that specific subheading.
You can still use the SEO Writer 100% identically to how you used it prior to SERP scraping. But the way you use the global background should change when you’re SERP scraping.
The AI needs meat to write about niche subjects and go deep on those subjects. Without SERP scraping, you’d supply that meat in the global background (up to 1,200 words) or in a particular subheading’s background (up to 500 words).
But with SERP scraping, you no longer need a long global background. In fact, it’s actually harmful and a waste of money. The rule of thumb when using SERP scraping is…
Why?
Remember how I mentioned (a few paragraphs above) about those “discussion points” which are generated for each subheading using the summaries generated from the SERP?
Since those discussion points are subheading specific (e.g., new discussion points are generated for each subheading) they are so much more useful than some monster 1,200 word global background where only bits and pieces may apply to a subheading.
In addition, the added benefit of the discussion points is they avoid repetition. A common complaint of using a long global background on a 10+ subheading article is duplicated content within different subheadings. But this is usually non-existent when using the SERP scraping feature.
TLDR: When you’re using the SERP scraping in the SEO Writer, don’t use a long global background; about 75 words is plenty.
Once you press the SERP scraping button, you’ll see a “Scrape the SERP Now” button (which isn’t present in the menu in the Bulk Writer).
Pressing this button is the first way to initiate a SERP scrape of the blog post title.
When you press this button, the menus will close, and ZimmWriter will scrape the SERP for your blog post title. Once complete, ZimmWriter will add the following:
Scraping the SERP ahead of time (like you just did) lets you now use “option 3” to generate your subheadings based on the global background from the SERP + the competition subheadings.
When you’re ready to have ZimmWriter write the article, you can press either button at the bottom of the SEO Writer menu (i.e., the “Start SEO Writer (with scraping URLs)” or “Start SEO Writer (no scraping URLs)” and it will use the scraped SERP data to write the article.
Using the “Scrape the SERP Now” button is optional. You can instead enable SERP scraping, generate your outline, fill in all the details, configure all the options, and then press either the “Start SEO Writer (with scraping URLs)” or “Start SEO Writer (no scraping URLs)” buttons.
What will happen?
ZimmWriter will first scrape the SERP (since it wasn’t already pre-scraped like discussed above), then it will write your article.
Make 100% sure your OpenAI account is at Usage Tier 2. Otherwise you will find that SERP scraping is VERY slow. You can find your rate limit in the upper left of this page.
You can easily reach Usage Tier 2 by simply adding $50 to your OpenAI account. You can read more about Usage Tiers and rate limits on the OpenAI Rate Limit page.
In general, assuming you’re on Usage Tier 2, scraping the SERP (before ZimmWriter starts writing your article) can take anywhere from 5 minutes to 20 minutes. Note that once the SERP scrape and webpage scrapes are stored in the cache, this time is reduced to zero.
When ZimmWriter encounters a “new” domain for a webpage it will assume that it doesn’t need any fancy ScrapeOwl settings (such as premium proxies, javascript, etc). It will try to scrape the webpage with just the default settings, at 1 credit a successful scrape.
But sometimes the webpage won’t scrape because the domain blocks the scraper, or it uses JavaScript to render the content, etc.
So what ZimmWriter does is the following:
Note: Each attempt can take up to 60 seconds before timeout and failed attempts do not cost ScrapeOwl credits!
If at any point ZimmWriter is successful in scraping the webpage, and premium proxies, render_js, or block_resources, were required, then ZimmWriter will save the domain to the ScrapeOwl settings with that configuration.
If scraping was not successful, then ZimmWriter will still add the domain to the ScrapeOwl settings menu but with a blocked status, which means the domain will be skipped if encountered during a SERP scrape in the future.
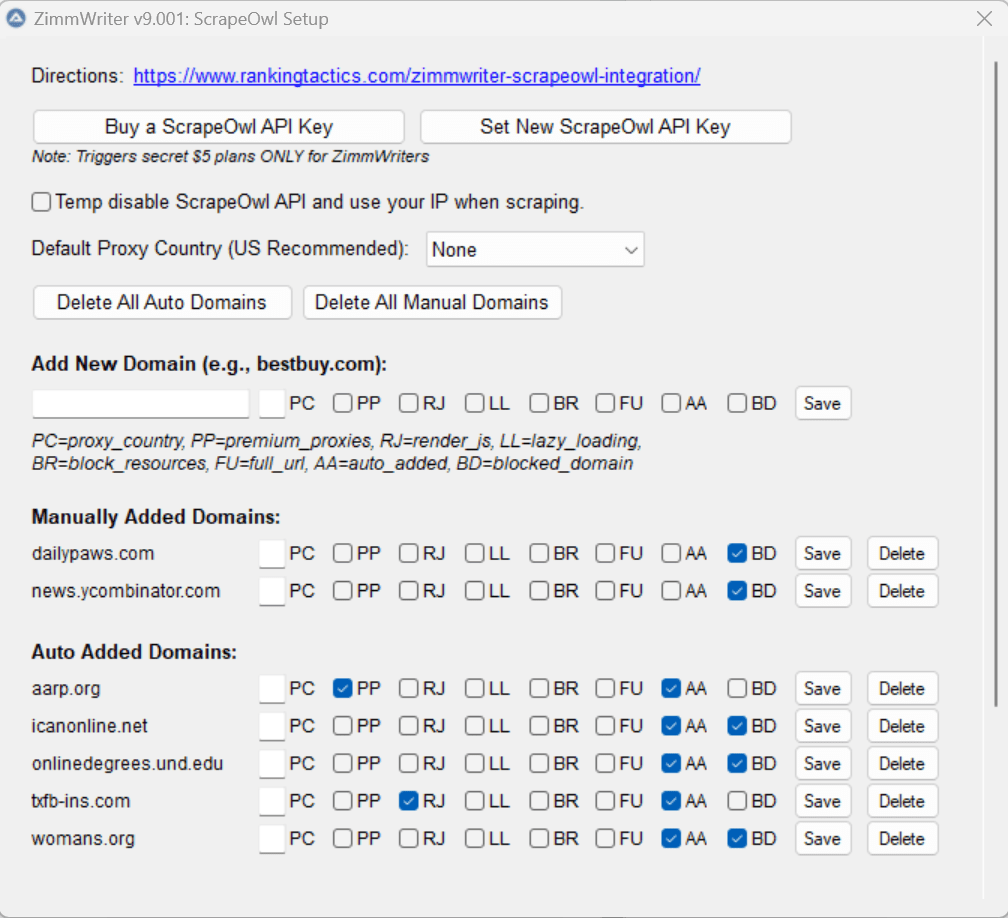
See the “auto added domains” area? All of those are domains which ZimmWriter encountered when scraping, struggled with, and then added to the database with a particular setting.
At the moment, ZimmWriter can hold up to 50 auto added domains. Once the limit is hit, the oldest added domains are removed to make room for the newer ones. First in, first out.
If you happen to encounter a domain a lot during SERP scraping, you can uncheck the “AA” box, press save, and then that domain will be added to the “manually added area”. Same limit of 50, but those domains are not auto removed.
The information provided on this website is provided for entertainment purposes only. I make no representations or warranties of any kind, expressed or implied, about the completeness, accuracy, adequacy, legality, usefulness, reliability, suitability, or availability of the information, or about anything else. Any reliance you place on the information is therefore strictly at your own risk. Read more in my terms of use and privacy policy. You can also contact me with questions.