
by Matt Zimmerman

In essence, Scraping Surgeon is a way to designate, with surgical precision, what sections on a webpage you want ZimmWriter to feed to the AI. It requires ScrapeOwl and a knowledge of CSS (or assistance by someone that does).
Sounds interesting. But what’s the point?
It’s best to explain with an example. Imagine an Amazon product page for an iPhone 15 Pro Max.
The product page will have information on the iPhone 15 Pro Max, but it will also have information on other iPhone models, iPhone accessories, and maybe even other phones. It could even have information on products other people bought along with the iPhone.
If ZimmWriter (or any AI writer for that matter) scrapes the entire page and sends the entirety of the scraped data to the AI for summarization, that’s a problem. The problem is twofold:
Scraping Surgeon is a way to filter out all of that extraneous information and only scrape relevant information.
The heart of Scraping Surgeon is the use of Cascading Style Sheets (CSS) ID and/or classes to identify which content you want scraped on a webpage.
You might have 0% idea about CSS and that will make it very difficult to setup new Scraping Surgeon domains without assistance. At the very least (and this requires zero CSS knowledge) you should add your Amazon affiliate tag to the default Amazon profile (in the Saved Domains dropdown) and then press the update button. After doing that, probably don’t mess with Scraping Surgeon unless someone helps you.
But if you’re feeling daring, and live for adventure, then here is a primer on HTML and CSS. A basic knowledge of each is required to use Scraping Surgeon.
HTML is the stuff you see when you right click on the background of a webpage inside Chrome and select “view page source”.
<h1>Apple iPhone 15 Pro Max, 1TB</h1>
The code above is called HTML and it has various “tags”. In the example above:
While there are many HTML tags, some of the more common ones include:
An HTML tag is like the inner-components of a car; it’s not pretty, but you need the engine, shocks, and drive shaft or the car will not operate.
Most people care more about how the car looks, then how it functions. Those “looks” are defined by CSS.
Cascading Style Sheets (CSS) are like the outer shell of a car and gives a webpage its stylish look.
Styling a page uses what’s called CSS selectors. The two most common are ID and class selectors. The best way to think of ID and class selectors are as keywords a webpage developer defines.
How it works is you’d add some CSS selectors to your HTML tags, and those selectors (keywords) would link back to a CSS file which defines each keyword using CSS code. Sounds complex, but it’s not. Let me give you a very simple example.
Webpage HTML:
<h1 id="productTitle" class="center">Apple iPhone 15 Pro Max, 1TB</h1> <p class="center tagline">Here are some product details on the new apple iPhone!</p>
Webpage CSS file:
#productTitle {
font-weight: 600;
font-size: 28px;
}
.center {
text-align: center;
}
.tagline {
font-weight: 400px;
font-size: 22px;
}
A CSS ID selector should only appear one time in the HTML. In this case, it’s productTitle and it’s assigned to the <h1> tag. Notice how it appears as id=”productTitle” in the HTML but as #productTitle in the CSS file.
A CSS class selector can appear multiple times in the HTML. In the example above, it’s assigned to the <h1> tag and also the <p> tag. Notice how it appears as class=”center” in the HTML but as .center in the CSS file.
Looking closely, you’ll also see that it’s possible to assign multiple classes to a single HTML tag. In the paragraph tag, we assigned both the center class and tagline class, separated by a space.
The last critical concept to understand for Scraping Surgeon is the concept of nested HTML tags.
<div> <p>Here is some text</p> <p>Here is some more text</p> </div>
Notice how the parent div tag contains two child paragraph tags. The paragraph tags are contained within the div tag (and are therefor child tags) because they occur after the opening <div> tag but before the closing </div> tag.
The reason this matters for Scraping Surgeon is because when we refer to a parent tag, Scraping Surgeon will scrape all of content inside of the referenced tag, including its children. Please remember this point as it’s critical to grasp.
Scraping Surgeon is located in the ZimmWriter Options menu because it’s a “set and forget” feature. When ZimmWriter scrapes a webpage, if a “domain” saved in Scraping Surgeon (with the “enable” box checked) matches the domain of webpage being scraped, then Scraping Surgeon is used to scrape the webpage.
A domain has the following rules:
You can specify either a single CSS class (.class) or ID (#id) that represents the element (or parent element) containing the title of the page or instead specify one of the HTML tags h1 or h2.
In the Amazon example below, I decided not to specify the HTML tag h1 because sometimes Amazon pages have multiple h1 tags and that would throw off the AI.
So I opted for a CSS ID #productTitle which usually always appears with an Amazon product title. An example of the HTML code is as follows:
<h1 id="title" class="a-size-large a-spacing-none"><span id="productTitle" class="a-size-large product-title-word-break">Apple iPhone 15 Pro Max, 1TB</span><span id="titleEDPPlaceHolder"></span></h1>
Notice how the title content “Apple iPhone 15 Pro Max, 1TB” is surrounded by the HTML span tag with an id=”productTitle” defining it. I’ve looked at various Amazon product pages, and they all seem to use this ID to designate the product title.
What if I were to have used the class “.product-title-word-break” instead of the ID that I found? Well, the “.product-title-word-break” class is repeated many times on an Amazon product page. So it’s a bad choice since it will contain many things other than just the product title.
So the trick is to find CSS classes and IDs that generally only refer to the item you want scraped and are consistent across many similar webpages on the same domain (e.g., all Amazon pages use those same designators for the elements).
The image class (.class) or ID (#id) is optional. If you decide to use it, then it applies in these situations:
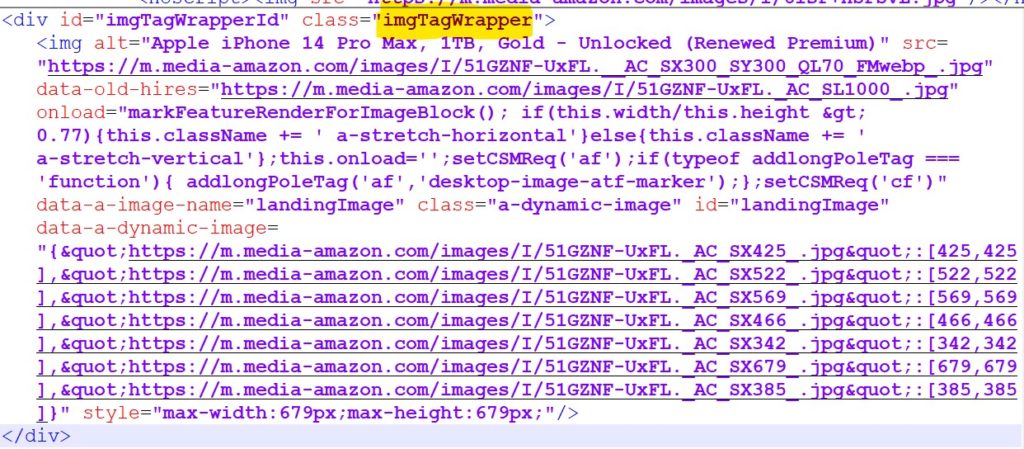
The selector I chose for the image was #imgTagWrapper. The <div> tag is a parent because it contains the <img> tag with the image we want.
ZimmWriter allows you to specify up to five CSS classes and/or IDs and/or HTML tags p, h2, ul, ol, li, section, span representing various sections on the page with text you want scraped.
Separate any CSS elements and HTML tags with a comma.
Here is the list that ZimmWriter uses (at the time of this writing) for Amazon:
#feature-bullets, #productDescription_feature_div, #prodDetails, #tech, .review-text
You can freely mix and match CSS selectors with the allowed HTML tags. Here is an example:
#feature-bullets, p, #prodDetails, ol, .review-text
For an Amazon domain, simply add your affiliate code. It should appear as a string of characters, a dash, and then some numbers (e.g., abc034-20).
For any other domains, you can add whatever you want to append at the end of a URL.
How does this play out when running ZimmWriter?
This string and/or affiliate code is used for the call to action in ZimmWriter. At the moment, ZimmWriter creates a call to action button in two instances:
At the moment, this setting only applies to Penny Arcade when not using the original title. It will cause the AI to write the title using the word “review” somewhere in it.
As an example, let’s say you’re scraping an Amazon page for an “iPhone 15 Pro Max”.
Without “treat as review” enabled, ZimmWriter might create a Penny Arcade article titled “iPhone 15 Pro Max: Incredible Features and Solid Performance”.
With “treat as review” enabled, ZimmWriter might create a Penny Arcade article titled “iPhone 15 Pro Review: Incredible Features and Solid Performance”.
Enable the domain for Scraping Surgeon detection or uncheck it to disable it. You can also delete the domain from Scraping Surgeon, but unchecking the “enable” box might be more useful in some situations.
You can save up to 50 domains in Scraping Surgeon. Again, it’s set and forget. You don’t need to “load” a domain. As long as the domain is saved with the enable box checked, then it’s valid for detection when scraping anywhere in ZimmWriter.
Press the save button to save a new domain for Scraping Surgeon.
Press the update button to save any changes you’ve made to an existing domain.
Press the delete button to delete the domain.
The information provided on this website is provided for entertainment purposes only. I make no representations or warranties of any kind, expressed or implied, about the completeness, accuracy, adequacy, legality, usefulness, reliability, suitability, or availability of the information, or about anything else. Any reliance you place on the information is therefore strictly at your own risk. Read more in my terms of use and privacy policy. You can also contact me with questions.